Unsupervised pretraining
In the early development of neural networks, the initialization of parameters was performed by sampling a uniform distribution bounded to a predetermined interval. In this process, the weights and biases produced solutions that would generally lie far from an optimum set of parameters, requiring many training iterations to readjust. Shallow networks did not suffer too much from this due to the smaller number of parameters, hence presenting an easier system to optimize. However, as the depth of networks increased, so did the difficulty to train such models using this initialization procedure.
Glorot and Bengio (2010) promoted a study to understand why random initialization performed so poorly in deep networks. In this investigation, the authors considered one common initialization heuristic, introduced by LeCun et al. (1998), that defines the biases at 0 and the weights via sampling according to the following uniform distribution:
$$W_{ij}\sim U\left[-\frac{1}{\sqrt{n}},\frac{1}{\sqrt{n}}\right]$$
where $n$ is the number of inputs to the unit. The authors then verified that in deep configurations of 4 to 5 layers, activation values on the last layers got stuck in plateaus situated at the extremes of the activation function, a case otherwise known as saturation.
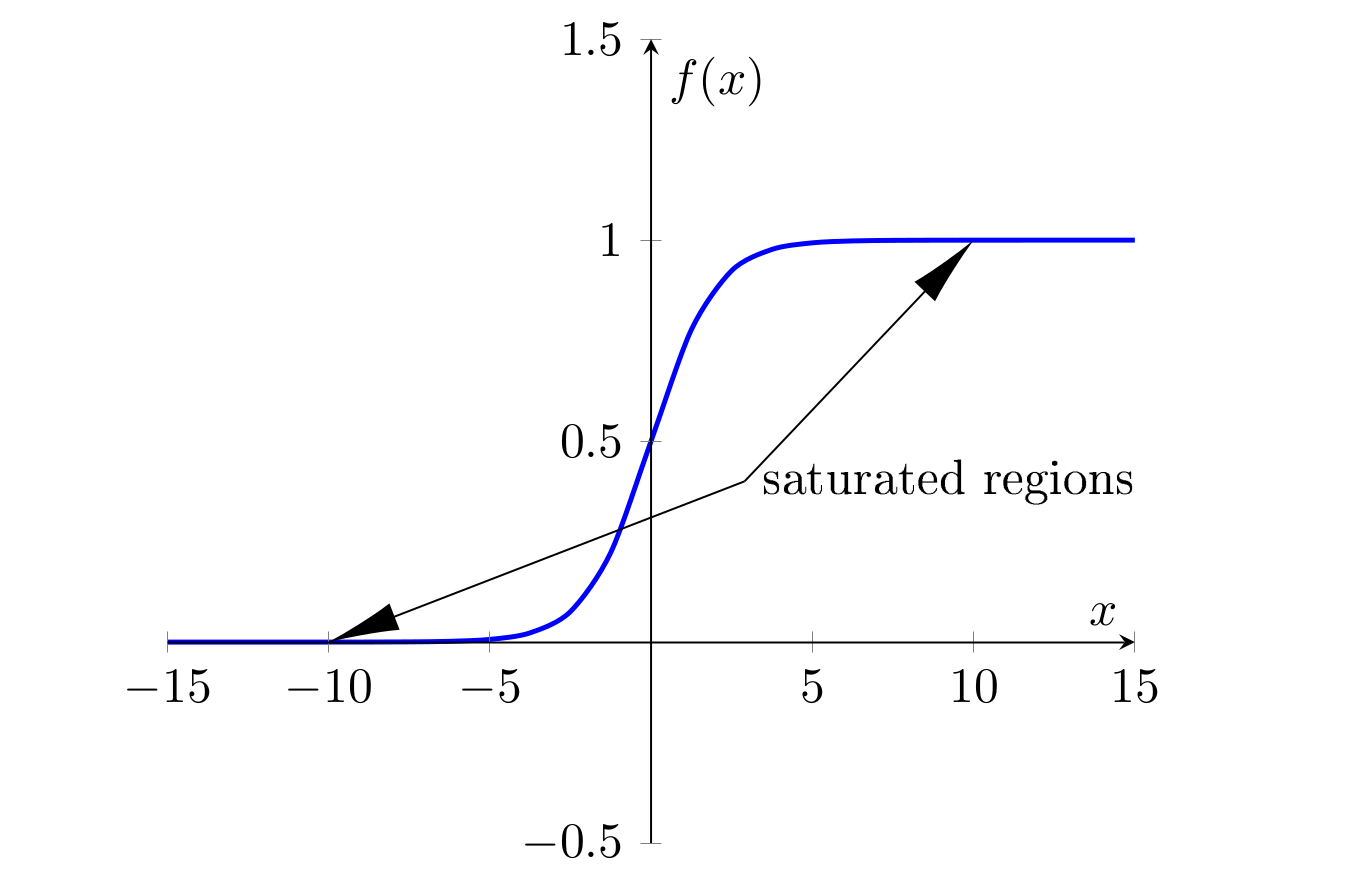
Saturation regions on the sigmoid function. In the case observed by Glorot and Bengio (2010), the saturation occurred in the 5th and last layer of the network, with activation values converging to zero.
One hypothesis that explains saturation on sigmoid-equipped deep networks is that the random initialization does not provide useful information to the last layer of the network, that starts to suppress the previous contributions and rely more on its biases, which, in turn, are trained faster than its weights.
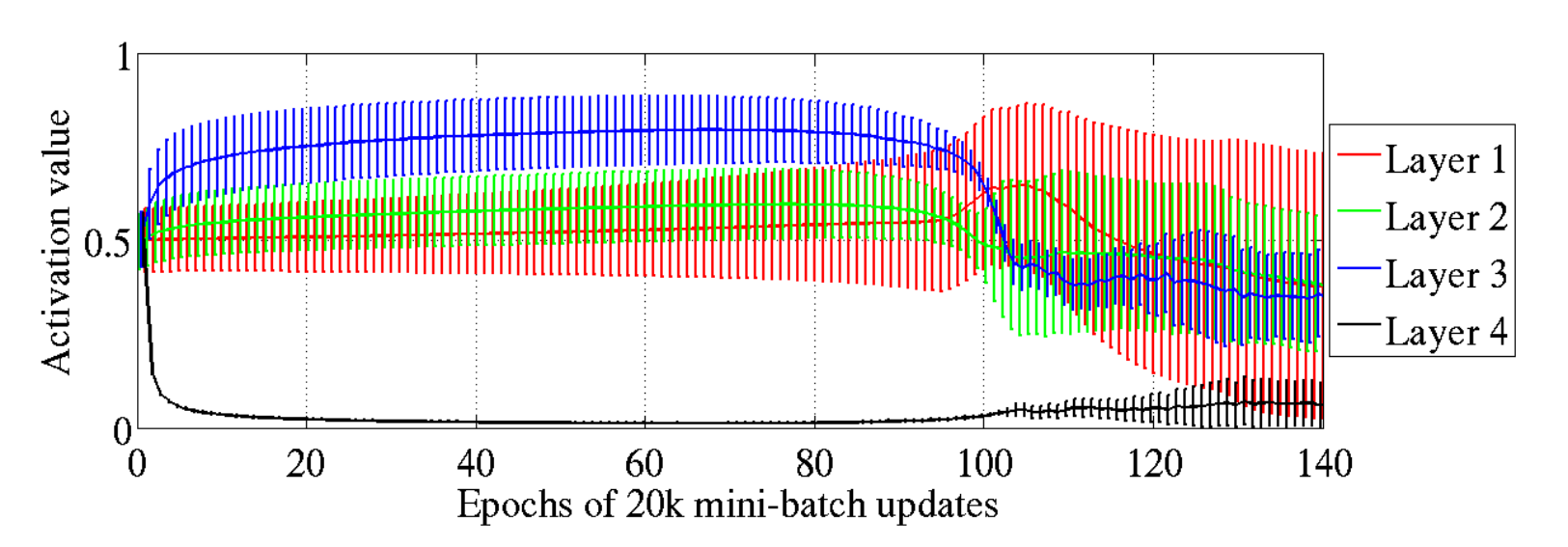
Mean (lines) and standard deviation (vertical bars) of sigmoid activation values across layers in a neural network using random initialization. The saturation is detectable in the last layer, where the activation values reach virtually zero. Source: Glorot and Bengio (2010)
Gradually but rapidly, the error gradient tends to push the activations towards zero in an attempt to suppress the influence of the previous layers. Eventually, the saturation may be overcome but the overall result would be of poor generalization.
Unsupervised pre-training
Layer saturation was one of the biggest technical hurdles that limited the progress of deep learning in the dawn of the millennium. However, in 2006, inspired by a well-established procedure, Hinton et al. (2006) developed a novel approach to initialize the parameters of a Deep Belief Network — a class of neural networks — that overcame the saturation issue and surpassed state of the art performance in deep architectures. These results not only re-sparked but drastically expanded researchers’ interest in this field.

A Deep Belief Network (DBN) can be seen as a stack of smaller unsupervised learning algorithms named Restricted Boltzmann Machines. This configuration can then be bundled with a classical multi-layer perceptron for supervised learning tasks
This initialization procedure encompassed an unprecedented process: an unsupervised greedy layer-wise pre-training step1. Prior to the conventional supervised training, each layer is trained with its anterior neighboring layer identically to a Restricted Boltzmann Machine, using an unsupervised learning algorithm named Contrastive Divergence. This process starts with the input and first layer, and progressively advances one layer at a time until it sweeps all layers.
A Boltzmann Machine is an unsupervised generative algorithm that learns the data representation by associating the patterns identified in the inputs to probabilistic configurations within its parameters. A Restricted Boltzmann Machine is a variation of such a model that reproduces a similar behavior but with significantly fewer connections.
1 Despite the imprecision, unsupervised pre-training is here used interchangeably

A Boltzmann Machine (left) and a Restricted Boltzmann Machine (right)
Many other unsupervised pre-training algorithms were developed concomitantly or immediately after, such as autoencoders (Bengio et al. (2007)), denoising autoencoders (Vincent et al. (2008)), contractive autoencoders (Rifai et al. (2011)), among others.
Comparison of performance between networks running without pre-training (left) and with pre-training (right)
Source: Erhan et al. (2010, pg. 636)
Why does this unsupervised learning methods help training deep architectures? Much of the explanation remains uncertain. Nonetheless, Erhan et al. (2010) provide some clarifications through considerable experimentation. The claims of the authors reside on two possible but not mutually exclusive reasons: optimization and regularization.
Deep neural networks are composed of many parameters whose values are used to compute an approximation of a function. Due to its substantial nonlinear nature, this approximation yields a non-convex function that poses a challenge on searching the best combination of weights and biases.2
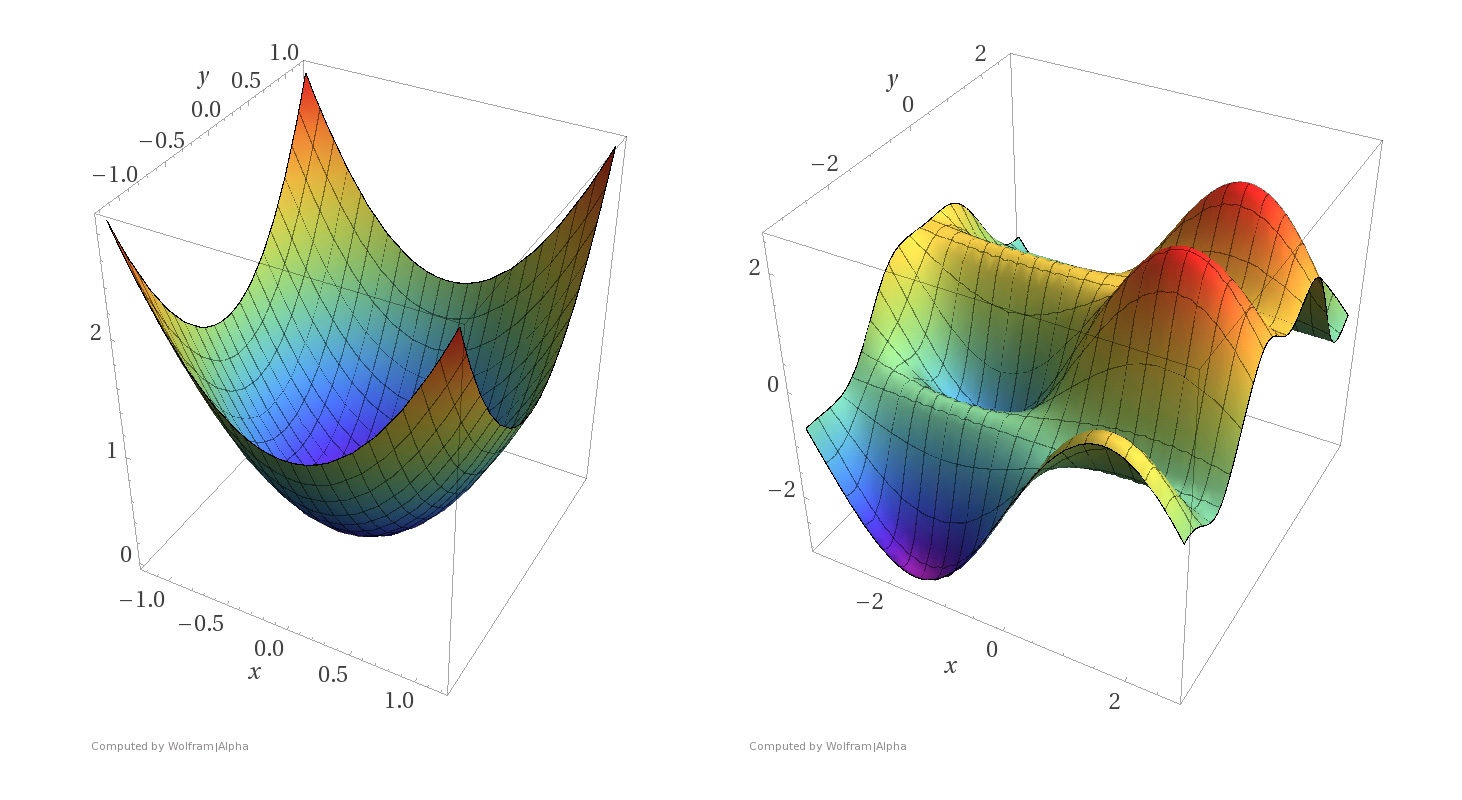
A convex (left) and non-convex (right) function. Note that, contrarily to the convex function, the non-convex function possesses multiple local optima. Source: [Zadeh (2016)](#References)
2 Many discussions today in academia evolve around the particular shape of loss landscape in deep neural networks, since many of the local minima appear to have equally good qualities, suggesting that the critical solutions reached during training are actually saddle points. This discussion will be reserved to further studies.
Gradient-based methods employed in training eventually converge to their pre-selected basin of attraction, a region of the function space, such that any point in it eventually is iterated into the attractor (roughly speaking, a valley in the loss function). Unsupervised pre-training may work towards optimization by favoring a basin of attraction that might yield a lower training error. Thus, since the gradients are very prompt to abrupt changes, backpropagation is only used at a local search level, from an already favorable starting point (Hinton (2012, lecture 14b)).
As for regularization, one may commonly associate it with explicit techniques, such as the L1 or L2 norm:
$$C=-\frac{1}{n}\sum_{j}\left[y_j\ln a_j^{L}+\left(1-y_j\right)\ln\left(1-a_j^{L}\right)\right]+\frac{\lambda}{2n}\sum_iw_i{{}^2}$$
By adding the L2 regularization factor in the cross-entropy cost function, presented in the equation above, one can penalize overly complex models, that would result in poor generalization, i.e. high testing error. However, the regularization employed by pre-training is implicit. In attempt to model how such technique would work explicitly, Erhan et al. (2009) defines a regularization term such as:
$$regularizer=-log\thinspace P\left(\theta\right)$$
The function $P\left(\theta\right)$ describes the probability that the weights of the neural network are initialized as $\theta$. So, if a configuration shows to be highly improbable, the regularizer term will hurt the cost function strongly. Furthermore, if the probability of landing such set of parameters is high, the regularizer will then reward the cost function. This probability is governed by the initialization methods employed. Considering two instances with and without pre-training, we obtain:
$$P_{{\text{pre-training}}}(\theta) = \sum_k\frac{1_{\theta \in R_k}\pi_k}{v_k}$$
and
$$P_{{\text{no pre-training}}}(\theta) = \sum_k\frac{1_{\theta \in R_k}r_k}{v_k}$$
where $R_k$ is the basin of attraction that contains $\theta$, and $1_{\theta \in R_k}$ is the identifier function – unitary for all $\theta$ in $R_k$, otherwise null. Additionally, $\pi_k$ and $r_k$ are the probabilities of landing in the basin of attraction $R_k$, which has a volume $v_k$. Since the basins of attraction are disjunct sets, the probability density function of the set of parameters located in $R_k$ is uniform, calculated by taking the probability of landing in the k-th basin ($\pi_k$ or $r_k$) and dividing by its volume.
Pre-training the parameters of the network conditions the network initialization to land on regions of better generalization. This is hypothetically achieved by increasing the $\pi_k$’s where the network parameters represent meaningful variations of the input, contributing to predict the output. For this reason, pre-training also reduces the variance upon parameter initialization.
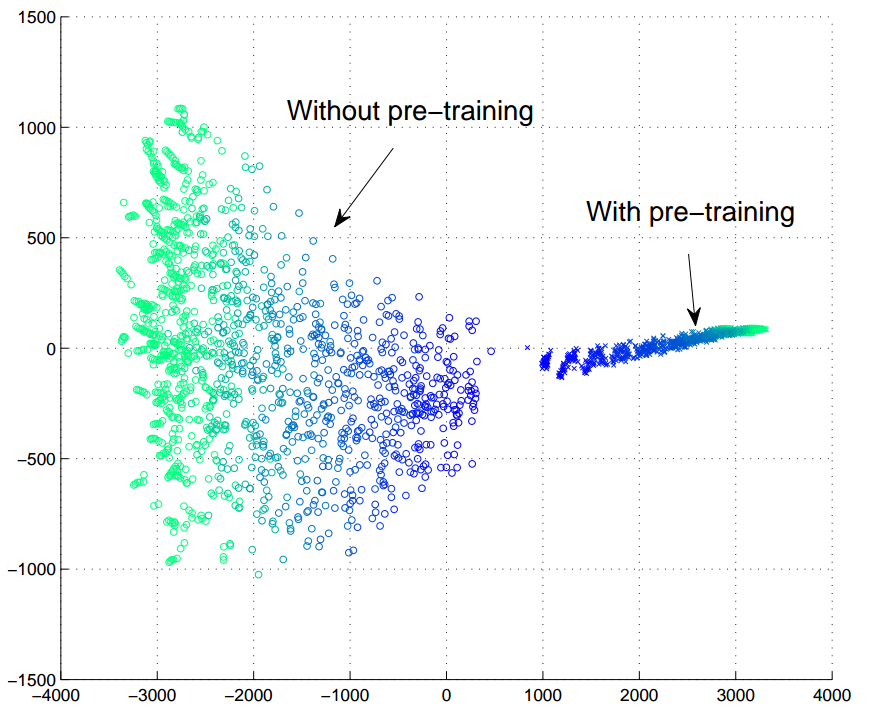
2-D visualization of parameters' trajectory of 100 neural networks with and without the unsupervised pre-training step. The color gradient from dark-blue to cyan symbolizes the progression of iterations.
Source: Erhan et al. (2010, pg. 541)
The visualization of the parameters’ trajectory may demonstrate the effects of optimization and regularization. As mentioned through the former, it may select a basin of attraction with lower training errors. Conversely, regularization may bound the parameter interval to a range that yields good generalization. Also, it is crucial to notice that both training and testing errors collected in the experiments of Erhan et al. (2010) support these hypotheses, but do favor the latter.
Furthermore, once established within the solution space, the parameters do not drastically change during the gradient-based adjustment process. This process is also denominated fine-tuning, as it only modifies the features slightly to get the category boundaries, rather than discovering new relationships (Hinton (2012, lecture 14b)).

Visualization of filters of a Deep Belief Network used to recognize digits form the MNIST data-set after the different training processes; from left to right: units from the first, second and third layers, respectively.
Source:Erhan et al. (2010, pg. 638-639)
But how can one conceptually understand the effects of unsupervised learning? Apart from the regularization and optimization hypothesis, the layer-wise pre-training resembles the underlying distribution of the input. Ideally, this representation, by combining the different features and mapping their inner relationships, can unveil, and more importantly, disentangle causal elements that influence the output. If those inputs can be transformed into uncorrelated features, it is possible to solve for a particular parameter disregarding its influence over the others.
As mentioned in Goodfellow et al. (2016, pg. 541), this hypothesis justify approaches in which one first seeks a good representation for $p(x)$ before training with the output. If the output is closely related to factors captured by the input, an initialization that captures the distribution of x is useful for predicting the desired output distribution $p\left(y|x\right)$.
Furthermore, unsupervised pretraining can be related with the recent work of Schwartz-Ziv and Tishby (2017) on studying neural networks from an information theory perspective. Essentially, the authors claim that the learning process of a neural network model is based on the maximizing the mutual information between the inputs and the outputs. Mutual information can be defined as:
$$I(X,Y) = H(X)-H(X|Y)$$
where $H$ is the entropy of the variable $X$:
$$H(X) = \mathbb{E}[-\log\thinspace(P(X)]$$
Entropy essentially measures the amount of information, i.e. the degree of uncertainty one has over a random variable. Moreover, when provided another random variable Y, we can measure the conditional entropy of X given Y:
$$H(Y|X)=-\sum _{x\in {\mathcal {X}},y\in {\mathcal {Y}}}p(x,y)\log {\frac {p(x,y)}{p(x)}} $$
Thus, mutual information is a statistical measurement between two random variables that indicate how much knowing one of these variables reduces uncertainty about the other. This, in turn, may have a connection with training neural networks as one begins the training stage knowing to little about the input and output, hence, having low mutual information stored in the neural network layers.
Mutual information measurements on 100-layer neural networks. Layer ordering ranges from green (initial layers) to orange (final layers). Source:Schwartz-Ziv and Tishby (2017)
However, as the training phase starts, the layers slowing move towards higher mutual information over $X$ and then towards $Y$. What happens in principle is that in the beginning, the network layers learn different representations over the input space, which in turn carry a lot of information over the input, but also some information about the output. As the training phase continues, the network layers, particularly the deeper ones, then discard some of the irrelevant information of $X$ which is not predictive of $Y$.
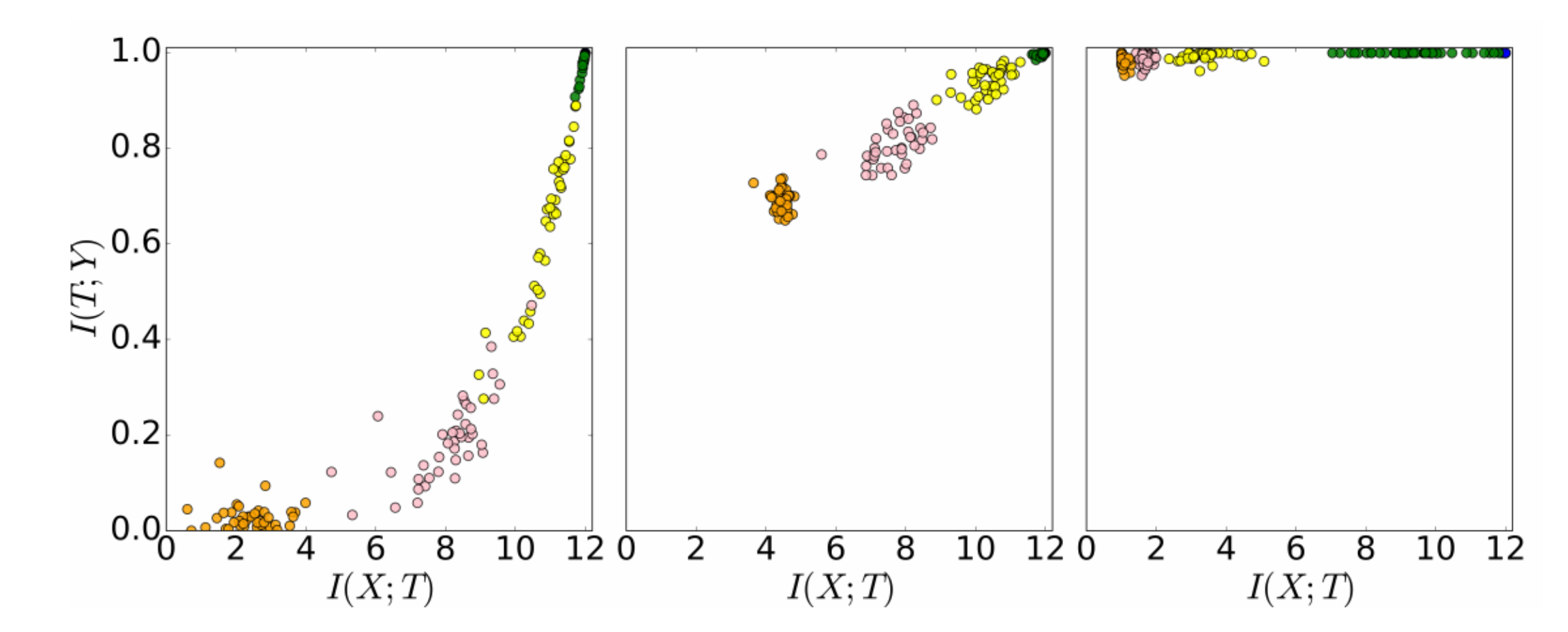
Snapshot of mutual information measurements along layers in different trainig epohcs. On the left, the neural network is at epoch zero, on the center at epoch 400, and the on right at epoch 9000. Source:Schwartz-Ziv and Tishby (2017)
The pretraining procedure can be related to the theory, particularly in the first part. By using an unsupervised learning algorithm, we may find a combination of parameters for each layer along with the network that shares higher mutual information with the input variable $X$ and consequently some with the output variable $Y$. As the gradient-based learning process continues, some of this information gets refined, as previously mentioned.
However, despite the aforementioned advantages, unsupervised pre-training presents noteworthy drawbacks, such as establishing two separate learning stages (unsupervised and supervised). As a consequence, there is a long delay between adjusting hyperparameters on the first stage utilizing feedback from the second. Additionally, although pre-training being considered a valuable regularizer, its strength adjustment is troublesome, requiring a somewhat unclear modification of far too many hyperparameters — contrasting with explicit regularization techniques that can be adjusted by a single one.
For the reasons mentioned above, unsupervised pre-training is not so popularly used today, as other techniques discovered yielded the same benefits but much more efficiently. These may be explained in a follow-up post, where we delve into initialization methods that not only tackle saturation but also a different obstacle: vanishing gradients.
References
- Bengio, Y. (2009). Learning Deep Architectures for AI. Foundations and Trends in Machine Learning. 1-127.
- Bengio, Y., Lamblin, P., Popovici, D., and Larochelle, H. (2007). Greedy Layer-Wise Training of Deep Networks. In Advances in Neural Information Processing Systems 19, 153-160.
- Erhan, D., Bengio, Y., Courville, A., Manzagol, P.A., Vincent, P., and Bengio, S. (2010). Why Does Unsupervised Pre-training Help Deep Learning? Journal of Machine Learning Research, 11-36.
- Erhan, D., Manzagol, P.A., Bengio, Y., Bengio, S., and Vincent, P. (2009). The Difficulty of Training Deep Architectures and the Effect of Unsupervised Pre-Training. Artificial Intelligence and Statistics, 153-160.
- Glorot, X. and Bengio, Y. (2010). Understanding the diffculty of training deep feedforward neural networks. Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics , pages 249-256.
- Goodfellow, I., Bengio, Y., and Courville, A. (2016). Deep Learning. MIT Press.
- Hinton, G. (2012). Neural Networks for Machine Learning. Coursera Online Course.
- Hinton, G. E., Osindero, S., and Teh, Y.-W. (2006). A Fast Learning Algorithm for Deep Belief Nets. Neural Computation , 1527-1554.
- LeCun, Y. A., Bottou, L., Orr, G. B., and Müller, K.-R. (1998). Efficient BackProp. Neural Networks: Tricks of the Trade, 9-48.
- Rifai, S., Vincent, P., Muller, X., Glorot, X., and Bengio, Y. (2011). Contractive Auto-encoders: Explicit Invariance During Feature Extraction. Proceedings of the 28th International Conference on Machine Learning, 833-840.
- Vincent, P., Larochelle, H., Bengio, Y., and Manzagol, P.-A. (2008). Extracting and Composing Robust Features with Denoising Autoencoders. Proceedings of the 25th International Conference, 1096-1103.
- Zadeh, R. (2016). The hard thing about deep learning. O'Reilly Media.
- Schwartz-Ziv, R. and Tishby, N. (2017). Opening the black box of Deep Neural Networks via Information. Featured on: Why & When Deep Learning Works: Looking Inside Deep Learning. arXiv:1703.00810v3